
🧠 기본적인 머신러닝 용어 정리
✅ Inference (추론)
이미 학습된 머신러닝 모델에 실제 새로운 데이터를 입력해서 예측(분석)하는 것을 말한다.
예시: ChatGPT에게 사진을 입력하여, 지브리 사진 만들어달라고 요청하기
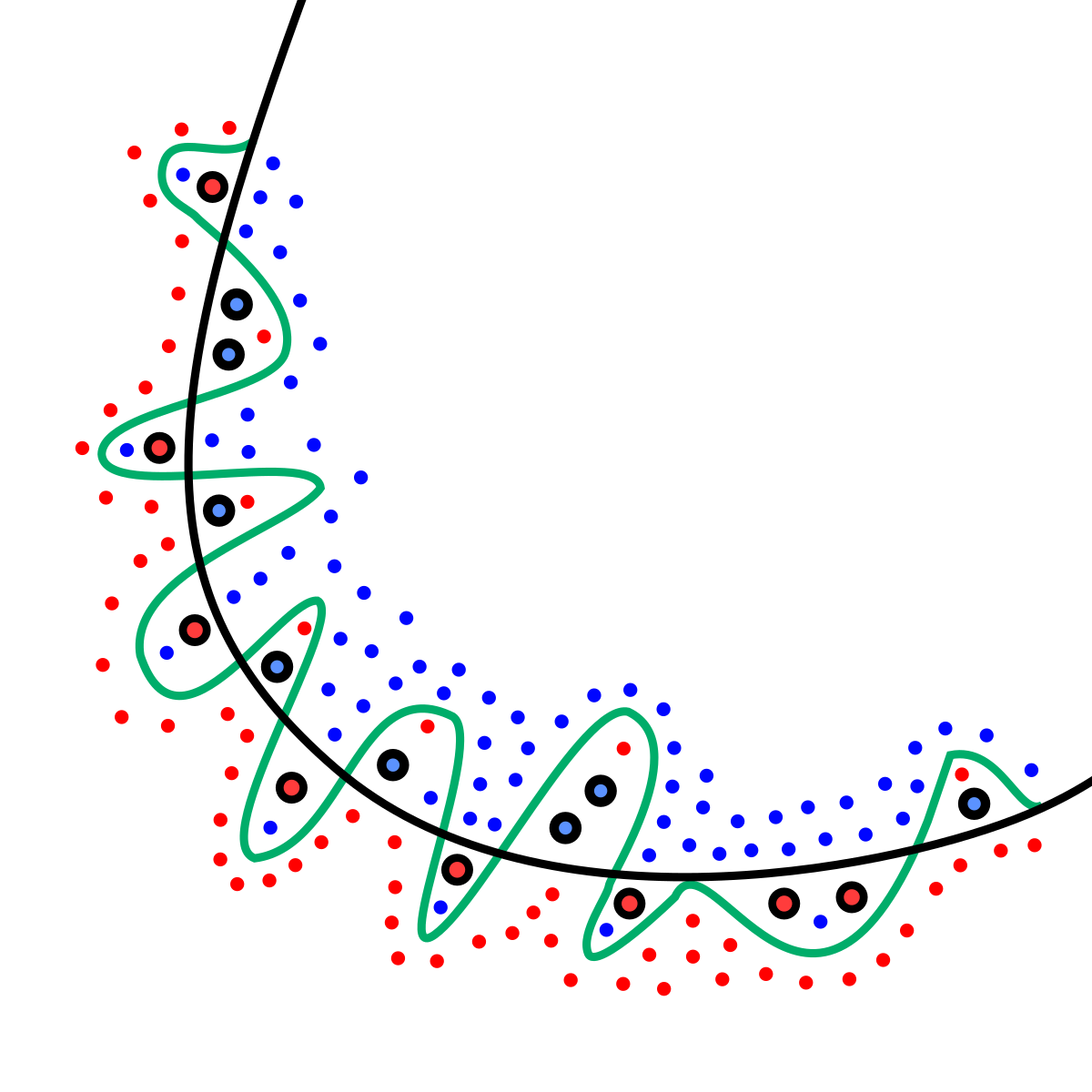
✅ Overfitting (과적합, 오버피팅)
머신러닝 모델이 훈련(training) 데이터에는 제대로 작동하지만, 새로운 데이터에는 성능이 떨어지는 경우.
| 훈련 데이터 | 실제 데이터 |
| ✅ | ❌ |

📌 주된 이유:
훈련 데이터에 있는 불필요한 특징(noise:노이즈)까지 학습해서, 다른 데이터에서는 제대로 인식하지 못한다.
📌 해결 방법:
- 더 다양한 데이터로 훈련시키기
- 같은 데이터로 너무 오래 훈련시키지 않기
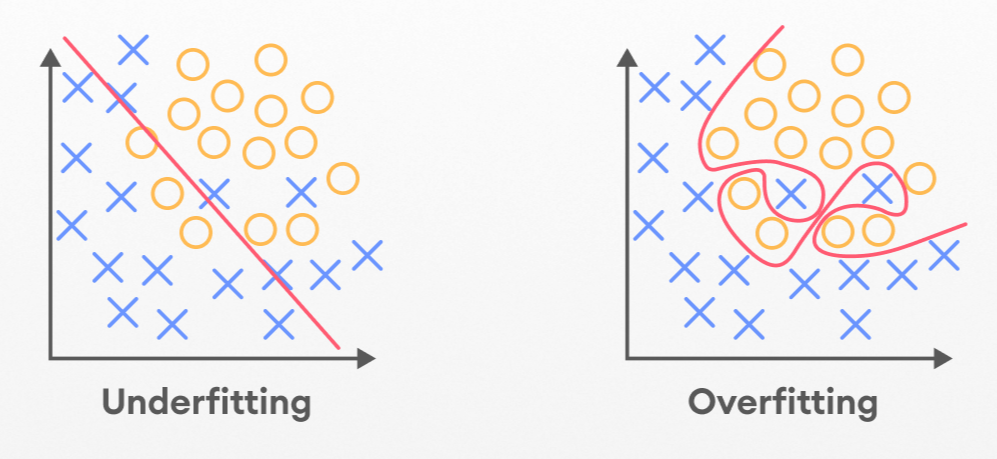
✅ Underfitting (과소적합, 언더피팅)
머신러닝 모델이 훈련 데이터에도, 새로운 데이터에도 성능이 낮은 경우.
| 훈련 데이터 | 실제 데이터 |
| ❌ | ❌ |
📌 주된 이유:
- 훈련 데이터가 너무 적어서 학습이 안됌
- 훈련 시간이 너무 짧아서 학습이 안됌
📌 해결 방법:
- 충분한 데이터 확보
- 적절한 학습 시간 설정
✅ Bias (편향, 바이어스)
Bias(바이어스)는 모델이 예측을 너무 단순하게 하려고 할 때 생긴다.
(머신러닝 모델의 예측이 불공정하거나 왜곡된 경우)

예시: "동물이 털이 있으면 고양이야."
예시와 같이 잘못 학습된 경우 Bias가 있다고 한다.

📌 Bias가 높은 경우: Underfitting (과소적합) 발생
→ 모델이 충분히 학습하지 못함
→ 훈련 데이터, 테스트 데이터 모두 예측이 잘 안 됨
📌 Bias가 너무 낮은 경우: Variance(분산)가 높아진다.
→ 이건 Overfitting (과적합)으로 이어질 수 있다.

✅ 머신러닝 모델의 퀄리티 높이는 방법
- 품질 좋은 데이터
- 다양한 데이터, 편향되지 않은 데이터 (예: 특정 나이, 성별만 있는 데이터는 안됌)
- 모델 설계 전에 공정성(Fairness) 고려
- 훈련 데이터와 결과를 지속적으로 평가
'클라우드(AWS) > AIF-C01' 카테고리의 다른 글
| [AWS] 머신러닝 파이프라인(ML Pipeline) 쉽게 정리 (0) | 2025.04.22 |
|---|---|
| RAG (Retrieval-Augmented Generation)란? 쉽게 정리 (0) | 2025.04.21 |
| 딥러닝(Deep Learning)이란? 쉽게 정리 (0) | 2025.04.15 |
| [AWS] Model Artifacts란? Inference 종류 (Real-time, Batch, Asynchronous, Serverless) 쉽게 정리 (0) | 2025.04.15 |
| [AWS] 머신러닝에 사용되는 데이터 유형 쉽게 정리 (0) | 2025.04.10 |