
🔧머신러닝 모델 훈련(training)을 끝낸 후에 할 작업들:
– 추론,예측 (inference)
– 배포 (deploy)
🧱 Model Artifacts (모델 아티팩트)
머신러닝 모델을 훈련시키면 (output) 결과로써 Model Artifacts(모델 아티팩트)라는게 생성된다.
Model Artifacts는 모델이 학습을 통해 얻은 핵심 정보들을 저장한 파일이다.
그리고 이는 학습된 모델이 예측(inference)을 할 수 있도록 준비된 형태의 데이터라고 보면 된다.
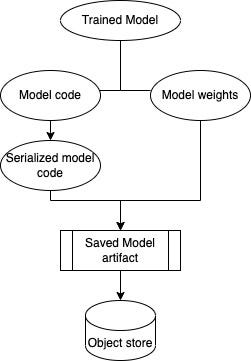

대부분의 머신러닝 모델은 Model Artifacts를 model.tar.gz 형태로 압축되어 저장한다.
✅ model.tar.gz 파일은 예측할 때 사용하기 때문에 어디에 저장했는지 잘 알아야한다.

✅ Model Artifacts에 포함되는 것들
AWS를 사용한다면 Model Artifacts 파일들은 보통 Amazon S3에 저장한다.
그다음, 이 Model Artifacts는 추론(inference) 코드와 함께 배포 가능한 모델로 패키징된다.
model.tar.gz
└── model/
├── model.pt # PyTorch 모델
├── inference.py # 추론 코드
├── preprocessing.py # 전처리 코드
├── config.json # 하이퍼파라미터
├── requirements.txt # 필요한 패키지 목록
├── metrics.json # 성능 정보
└── README.md # 모델 설명| 항목 | 설명 |
| 학습된 모델 파일 | 모델의 가중치와 구조 (예: model.pkl, model.h5, model.pt) |
| 추론(inference) 코드 | 모델을 불러오고 실제로 예측을 수행하는 역할의 코드 (예: inference.py) |
| 전처리 도구 | 학습 시 사용된 scaler, encoder 등 (예: scaler.pkl, tokenizer.json) |
| 하이퍼파라미터 설정 | 학습 시 사용된 설정 정보 (예: config.json) |
| 성능 지표 | 정확도, 손실률 등 평가 결과 (예: metrics.json) |
| 환경 정보 | 필요한 라이브러리 목록 (예: requirements.txt) |
| 모델 설명/메타데이터 | 작성자, 버전, 학습 날짜, 모델 설명 등 (예: README.md) |
🔹 Inference (추론)
- 추론은 모델이 새로운 입력 데이터를 받아서 결과(출력)를 생성하는 과정이다.
- 예를 들어, 챗봇에게 질문(프롬프트)을 하면, 모델이 답변을 만들어내는 과정이 바로 inference이다
(Amazon Bedrock에서는1.기본 모델(Base model), 2.사용자 정의 모델(Custom model), 3.프로비저닝 모델(Provisioned model)로 추론을 실행할 수 있다.)
🔹 Inference Parameters (추론 파라미터)
모델의 출력 특성(랜덤성, 다양성, 길이 등)을 조절하는 설정값이다.
주요 파라미터:
| 파라미터 이름 | 기능 |
| Temperature | 값이 높을수록 결과가 더 창의적,램덤해진다. (예: 1.0은 다양함, 0.2는 정해진 답에 가깝게) https://jibinary.tistory.com/707 |
| Top-K | 모델이 다음 단어를 고를 때 고려하는 후보 개수를 제한. (예: 상위 5개 단어 중에서 선택) |
| Top-P (nucleus sampling) | 누적 확률이 일정 수치(P) 이상이 될 때까지 상위 단어만 고려 |
| Max tokens | 생성되는 답변의 최대 길이를 제한 |
| Penalties | 반복을 줄이거나 특정 단어의 사용을 제한 |
| Stop sequences | 특정 문자열이 나오면 응답을 멈추도록 설정 (예: 딥싱크에서 시진핑 나오게하기) |
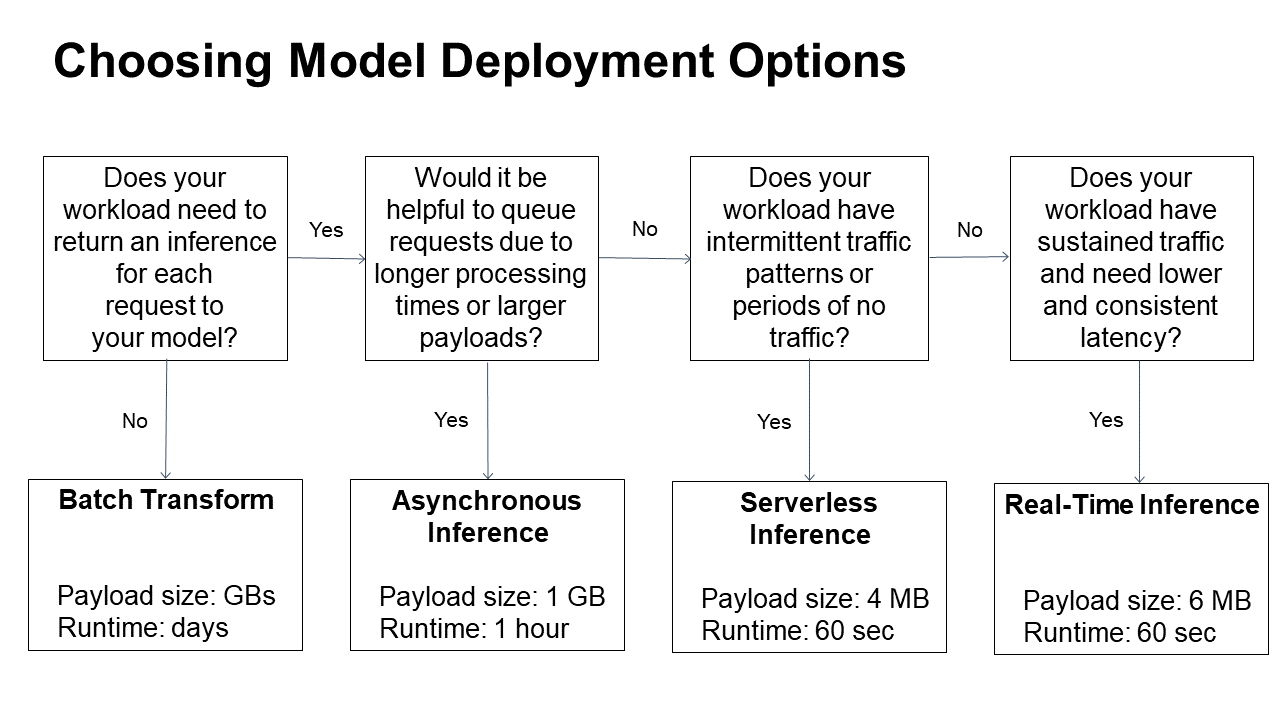
🖥️ 모델 Inference(추론) 방식: 실시간(Real-time) vs 배치(Batch)
| 방식 | 설명 | 예시 |
| Batch inference (일괄 추론) |
한꺼번에 많은 데이터를 추론하고 결과는 나중에 받음 | 하루치 데이터를 밤에 일괄 처리 |
| Real-time inference (실시간 추론) |
사용자가 요청하면 바로 응답 | 챗봇, 생성형 AI |
| Asynchronous inference (비동기 추론) |
요청만 받고, 처리 후 결과를 나중에 제공 | 대용량 이미지 처리 |
| Serverless inference (서버리스 추론) |
요청이 있을 때만 리소스를 사용해서 비용 절감 | 트래픽이 일정하지 않은 예측 서비스 |
1️⃣ 실시간 추론 (Real-time Inference)
실시간 요청을 빠르게 처리해야 할 때 사용된다.
항상 on으로 되어있는 엔드포인트에 모델을 배포해서, 요청이 오면 바로 추론(inference)을 해준다.
Real-time Inference는 낮은 Latency(지연시간)이 필요할 때 사용한다.
하지만 구축하기 좀 어렵고, 더 많은 비용이 든다.
Real-time Inference 예시: 챗봇 (예: Alexa, Siri, ChatGPT)


2️⃣ 배치 추론 (Batch Inference)
많은 데이터를 한 번에 처리할 때 사용한다.
예측을 빠르게 할 필요는 없고, 주기적으로 대량 데이터를 처리할 때 적합하다.
배치 작업이 끝나면 컴퓨팅 리소스는 자동으로 종료돼서 비용을 아낄 수 있다.
24시간 운영되야하는게 아니기 때문에 on/off를 할 수 있다.
Batch Inference 예시:
지난 달의 판매 데이터를 분석해서 다음 달의 재고를 예측하는 경우
예시: Real-time 추론 (Inference)
- 유저가 웹에서 요청을 보낸다.
- 웹에서 API Gateway를 통해 요청을 전송
- API Gateway가 Lambda 함수로 전달
- Lambda 함수가 Docker 컨테이너에서 모델을 실행하여 Inference 한다.
- Inference 결과를 웹 앱에 반환한다.
🤖 SageMaker를 이용한 배포 (자동화된 방식)
Amazon SageMaker는 모델을 자동으로 배포해준다.
- 📦 S3에 모델 아티팩트 (model.tar.gz 등)을 저장
- 🐳 ECR에 모델 실행 코드가 들어있는 Docker 이미지 저장
- 📡 SageMaker에서 어떤 추론 방식(예: Batch, Real-Time 등) 사용할지 설정하기
- 그러면 SageMaker가 알아서 endpoint를 만들어준다.
- EC2 머신 준비
- Docker 컨테이너 실행
- 엔드포인트 자동 생성
- 스케일링 설정 등 자동으로 해줌
'클라우드(AWS) > AIF-C01' 카테고리의 다른 글
| [AWS] Responsible AI란? 쉽게 정리 (0) | 2025.04.16 |
|---|---|
| 딥러닝(Deep Learning)이란? 쉽게 정리 (0) | 2025.04.15 |
| [AWS] 머신러닝에 사용되는 데이터 유형 쉽게 정리 (0) | 2025.04.10 |
| [🤖머신러닝] 지도(Supervised), 비지도(Unsupervised), 강화(Reinforcement) 학습 쉽게 정리 (0) | 2025.04.09 |
| [AWS] Amazon Q Developer란? 쉽게 정리 (0) | 2025.04.08 |