
◇ 공부 기록용으로 작성하였으니 틀린점, 피드백 주시면 감사하겠습니다 ◇

Auto Scaling이란?

Scaling(스케일링)이란 쉽게 서버의 컴퓨팅 파워를 늘리거나 줄이는 것을 말한다. 컴퓨팅 파워를 늘리는 방법에는 2가지가 있다.
- Scale Up (수직적 확장): 컴퓨팅의 성능을 높임.
- Scale Out (수평적 확장): 같은 성능의 컴퓨팅의 갯수를 늘림.
반대로 컴퓨팅을 줄이는 방법.
- Scale In (수평적 축소)
- Scale Down (수직적 축소)
AWS에서 Auto Scaling 사용할 수 있는 서비스 예시
AWS 측의 개발&관리로 인해 다양한 AWS 서비스에서 Auto Scaling이 가능하다.
- EC2
- RDS (Aurora)
- DynamoDB
- ECS
- 기타 등등
Auto Scaling Group (ASG)
Auto Scaling Group은 애플리케이션의 수요에 따라 EC2 인스턴스의 수를 자동으로 조정하는 기능이다.
이를 통해 리소스를 효율적으로 관리하고 비용을 최적화할 수 있다.
Launch Templates 과 Launch Configurations 차이
Launch Configuration은 예전 방식이고, Launch Template이 최신 방식이다.
그래서 기능면에서 Launch Template이 더 좋다.
| Launch Configuration | Launch Template | |
| 버전 관리 (Versioning) | ❌ 지원하지 않음 | ✅ 지원 |
| 사용 가능 리소스 | ❌ 일부 새로운 EC2 기능 지원 불가 | ✅ 최신 EC2 기능 지원 |
Auto Scaling Group 설정하는 법
- Launch Template 생성하기
- Auto Scaling Group 생성하기
- 생성한 Launch Template 연결
- VPC와 Subnet, Availability zone을 지정
- (optional) Load balancer 연동: Health checks 방식 설정
- Group size 지정 (Desired, Minimum, Maximum 인스턴스 수 설정)
- Scaling Policy 설정
자세한 내용
Step 1. 생성한 Launch Template 연결
Step 2. VPC와 Subnet, Availability zone을 지정
Step 3. (optional) Load balancer 연동: Health checks 방식 설정
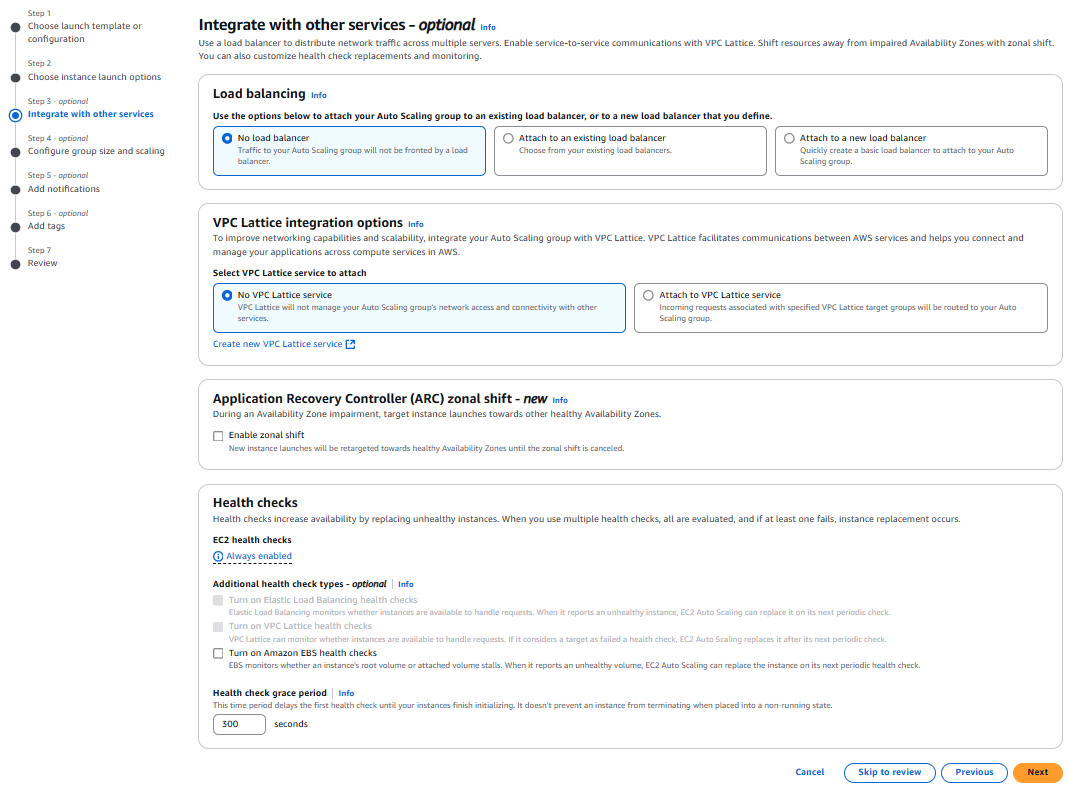
Step. 4 Group size 지정 (Desired, Minimum, Maximum 인스턴스 수 설정), Scaling Policy 설정
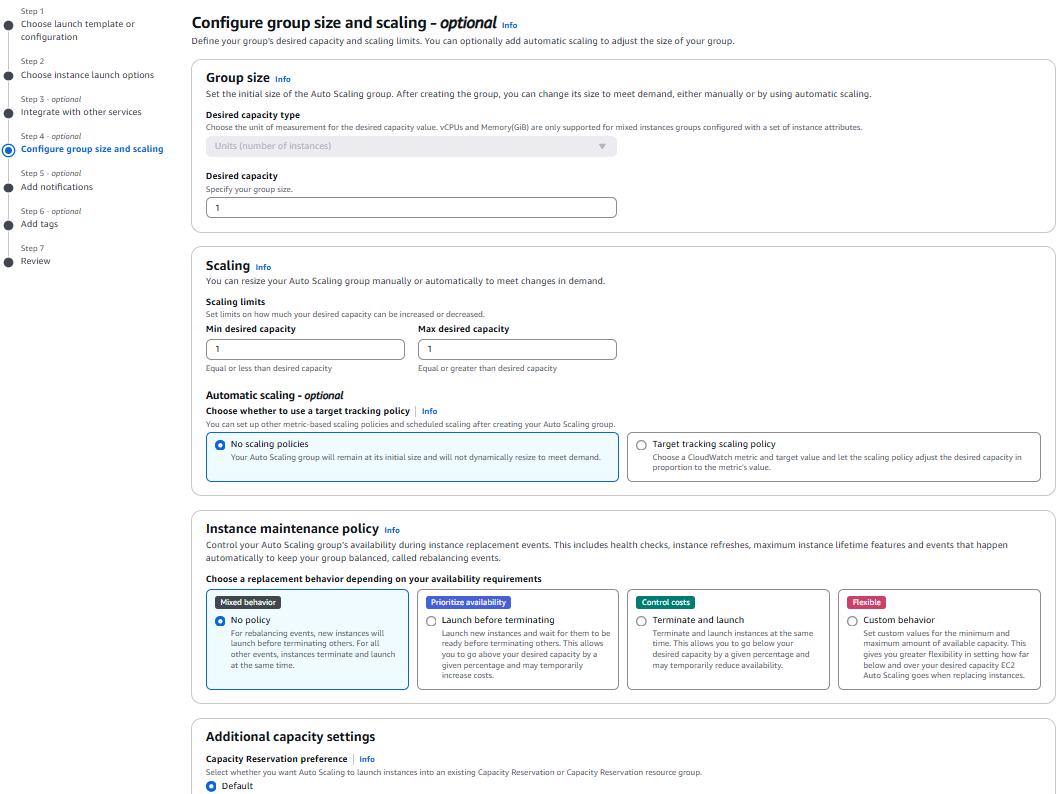
Set scaling limits for your Auto Scaling group
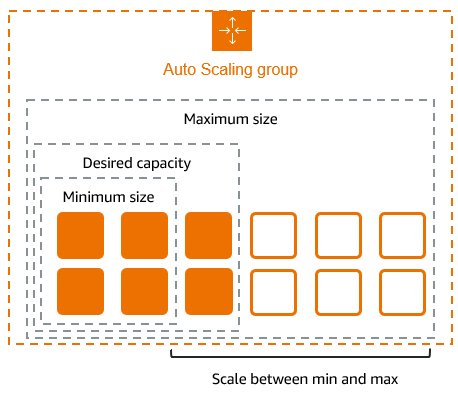
Scaling Limits (Group Size)
Minimum/Maximum/Desired Capacity의 파라미터에 따라 EC2 인스턴스 수를 자동으로 스케일링한다.
- Minimum Capacity (최소 인스턴스 수): 트래픽이 적더라도 설정한 인스턴스 수를 유지한다.
- Maximum Capacity (최대 인스턴스 수): 트래픽이 급증하더라도 이 수를 초과하지 않는다.
- Desired Capacity(유지하려는 인스턴스의 목표 수): ASG는 이 수를 유지하기 위해 인스턴스를 추가하거나 제거한다

Health Check
Health Check를 통해 리소스에 문제가 생겼을 경우 자동으로 새로운 리소스가 시작된다. (문제가 발생한 리소스는 자동으로 종료된다)

기본 설정으로 "EC2"가 활성화되어 있고, "ELB"는 비활성화되어 있다.
하지만 "EC2"와 "ELB" 모두 활성화하는 것이 권장된다.
📌 Health Check 유형: 인스턴스의 상태를 확인할 방법
- EC2 (Default) - 인스턴스의 Health Check 결과를 확인한다
- ELB - 지정된 연결 대상에 대한 Health Check 확인을 수행한다
📌 Health Check Grace Period: 인스턴스 시작 후 헬스 체크를 시작하기 전에 기다리는 시간(초).
참고: EC2는 ON, ELB는 OFF인 경우
만약 Auto Scaling Group의 Health Check 설정에서 "EC2"가 활성화되고 "ELB"가 비활성화된 경우, ELB에서 Health Check에 문제가 있어도, EC2의 Health Check가 정상이라면 인스턴스는 계속 실행된다.
예를 들어, ELB Health Check에서 지정된 URL에 문제가 발생(HTTP 404 오류 등)하더라도, 인스턴스 자체는 정상적으로 동작할 수 있으므로 ALB에서 부하가 분산되지 않게 되지만 인스턴스가 종료되지 않는다.
인스턴스가 종료되지 않으면 새로운 인스턴스가 시작되지 않아서 서비스가 중단될 가능성이 있다.
Health Check 설정에서 "ELB"도 활성화하면, ELB에서 Health Check에 응답하지 않는 인스턴스가 종료되고 새로운 정상 인스턴스가 시작됩니다.
Scaling Policy (스케일링 정책)
AWS 리소스의 부하 상태나 스케줄에 따라서 스케일링을 자동 또는 수동으로 실행 시킬 수 있다.
"Scaling Policy"을 통해서 어떻게 스케일링 할 건지 정의한다.
- Manual Scaling (수동 스케일링)
- Dynamic Scaling (동적 스케일링)
- Predictive Scaling (예측 스케일링)
- Scheduled Scaling (스케줄 기반 스케일링)
📈 1. Manual Scaling (수동 스케일링)
사용자가 수동으로 스케일링을 수행한다.
예시) 인스턴스 수를 3대로 설정
📈 2. Dynamic Scaling (동적 스케일링)
실시간 성능에 따라 자동으로 스케일링 된다.
예시) CPU 사용량이 90%가 되면 인스턴스 2대로 운영
스케일링 발생 조건에 따라 "Simple Scaling", "Target Scaling", "Target Tracking Scaling"으로 나뉜다.
2.1 Simple Scaling
2.2 Target Scaling
2.3 Target Tracking Scaling
📈 3. Predictive Scaling (예측 스케일링)
과거의 성능 데이터를 바탕으로 미래의 리소스 수요를 예측하여 최적의 리소스 수를 맞추도록 스케일링을 수행한다.
예시) 과거 1주일의 CPU 사용률 데이터를 기반으로 인스턴스 수를 조정하도록 설정
📈 4. Scheduled Scaling (스케줄 기반 스케일링)
일정한 날짜와 시간에 1회만 또는 정기적인 일정에 따라 스케일링을 수행한다.
예시) 매일 오전 8시 30분부터 인스턴스 수를 4대로 설정
Dynamic Scaling Policy
추가로 Dynamic Scaling에는 Scaling 방식이 또 나눠진다.
- Simple Scaling
- Step Scaling
- Target Tracking Scaling

1. Simple Scaling: 하나의 메트릭스 값 기준
특정 메트릭스(CPU 사용률 등 시스템 성능에 관한 데이터)에 대한 하나의 임계값을 기준으로 스케일링을 수행한다.
예시) 300초 동안 평균 CPU 사용률이 50%를 초과하면 인스턴스를 1대 추가하도록 설정
2. Step Scaling: 여러개의 메트릭스 값 기준 기준, 단계적으로 스케일링
특정 메트릭스에 대한 여러(mutiple) 임계값을 기준으로 단계적으로 스케일링을 수행한다.
예시) 300초 동안 평균 CPU 사용률이 50%를 초과하면 인스턴스를 1대 추가하고, 90%를 초과하면 2대를 추가하도록 설정
3. Target Tracking Scaling: 특정 메트릭스가 목표 값이 되도록 스케일링
특정 메트릭스가 지정된 목표 값이 되도록 스케일링을 수행한다. 인스턴스 수의 증감은 AWS에서 조정된다.
예시) 평균 CPU 사용률이 30%가 되도록 설정되어 있습니다.
Termination Policy 종료 정책 (Scale In 순서)
ASG가 스케일 인(Scale In) 할 때, 어떤 우선 순위로 인스턴스를 종료 시킬지를 정의한다.
- Default Termination Policy - 기본적으로 선택되는 규칙
- Custom Termination Policy - 따로 고급 설정으로 선택가능한 규칙
Default Termination Policy (📌기본)
Auto Scaling Group의 Default Termination Policy는 인스턴스를 종료할 때 자동(기본)으로 적용되는 규칙으로, 다음과 같은 조건을 순서로 인스턴스를 종료한다
- AZ Rebalancing: 먼저, Auto Scaling은 모든 가용 영역(AZ) 간의 인스턴스 수가 균형을 이루도록 한다. 특정 가용 영역에 인스턴스가 많다면 그 영역의 인스턴스를 우선적으로 종료한다.
- Oldest Launch Configuration: 여러 (Launch Configuration 또는 Launch Template)을 사용하는 경우, 가장 오래된 Launch Configuration으로 생성된 인스턴스를 우선적으로 종료한다. 이는 최신의 런치 구성을 유지하는 데 유용하다.
- Closest to Next Billing Hour: 위의 두 조건으로도 동일한 인스턴스가 여러 개 있을 경우, 다음 결제 시간이 가장 가까운 인스턴스를 종료한다. 이렇게 하면 비용 절약을 극대화할 수 있습니다.
- Random Selection: 위의 조건을 모두 만족하지 않는 경우에는 무작위로 인스턴스를 선택하여 종료한다.

Custom Termination Policy
- Newest Instance: 가장 최근에 시작된 인스턴스를 먼저 종료
- Oldest Instance: 가장 오래된 인스턴스를 먼저 종료
- Oldest Launch Configuration: 가장 오래된 Launch Configuration을 사용하여 시작된 인스턴스를 먼저 종료
- ClosestToNextInstanceHour: 다음 결제 청구 시간이 가장 가까운 인스턴스를 먼저 종료
Scale In 시 특정 리소스가 종료되지 않도록 하려면 "Instance Protection(인스턴스 보호)"를 활성화해야 한다



🤔 SAA 문제
다음과 같은 환경이 있습니다: 두 개의 가용 영역(AZ)에 걸친 Auto Scaling 그룹이 있고, AZ-a와 AZ-b로 불립니다. AZ-a에는 4개의 EC2 인스턴스가 있고, AZ-b에는 3개의 EC2 인스턴스가 있습니다. Auto Scaling 그룹은 기본 종료 정책(Default Termination Policy)을 사용하고 있습니다. 어떤 인스턴스도 축소(scale-in) 이벤트에서 보호되지 않습니다.
만약 축소 이벤트가 발생하면, Auto Scaling은 어떻게 진행할까요?
- Auto Scaling은 종료할 인스턴스를 무작위로 선택합니다.
- Auto Scaling은 모든 인스턴스 중에서 가장 오래된 런치 구성을 가진 인스턴스를 종료합니다.
- Auto Scaling은 4개의 EC2 인스턴스가 있는 가용 영역을 선택한 후 계속 평가를 진행합니다.
- Auto Scaling은 모든 인스턴스 중에서 다음 결제 시간이 가장 가까운 인스턴스를 종료합니다.
정답
정답. 3번
🤔 SOA 문제

회사는 새로운 워크로드를 시작하고 있습니다. 해당 워크로드는 Amazon EC2 Auto Scaling 그룹 내 EC2 인스턴스에서 실행될 예정입니다. 회사는 EC2 구성의 다양한 버전을 유지해야 하며, Auto Scaling 그룹이 CPU 사용률을 60%로 유지하도록 자동으로 확장되기를 원합니다. SysOps 관리자가 이러한 요구사항을 충족하려면 어떻게 해야 합니까?
- Auto Scaling 그룹이 Launch Configuration과 Target Tracking Scaling Policy를 사용하도록 설정합니다.
- Auto Scaling 그룹이 Launch Configuration과 Simple Scaling Policy를 사용하도록 설정합니다.
- Auto Scaling 그룹이 Launch Template과 Target Tracking Scaling Policy를 사용하도록 설정합니다.
- Auto Scaling 그룹이 Launch Template과 Simple Scaling Policy를 사용하도록 설정합니다.
정답
정답 3번
1번, 2번 (오답)
Launch Configuration은 버전 관리를 지원하지 않는다.
'클라우드(AWS) > EC2' 카테고리의 다른 글
| [AWS] key pair(키 페어)란?? 쉽게 정리 (0) | 2024.07.19 |
|---|---|
| [AWS] EC2 AMI를 다른 AWS계정으로 공유하는 법 (0) | 2024.05.31 |
| [AWS] User data와 Metadata란? 쉽게 개념 정리 (0) | 2024.05.30 |
| [AWS] EC2의 남은 용량 확인하기 (0) | 2024.05.13 |
| [AWS] EC2의 Placement Group란? 쉽게 개념 정리 (Cluster, Partition, Spread 차이점 비교) (0) | 2024.03.27 |